Introducing CSVJSON
The comma separated values (CSV) format is a simple textual data format that has been used for exchanging tabluar data between programs and systems for many years. There is even an RFC attempting to standardize this format - RFC 4180.
Still, the CSV format suffers from major shotcomings which make it hard to use reliably across programs and systems even today. These shotcommings include:
- Character encoding of string values is not specified
- There is no standard way to specify null values
- There are no standard escaping rules, in particular for values containing newlines
- There is no way to have object values, array values
All of that and more is solved by a trivially specified format CSVJSON
The CSVJSON format is based on the well-known and highly popular JSON format. For ‘simple’ data, CSVJSON is even compatible with the regular CSV format.
The definition of the CSVJSON format is trivial. Given the definition of a JSON array:
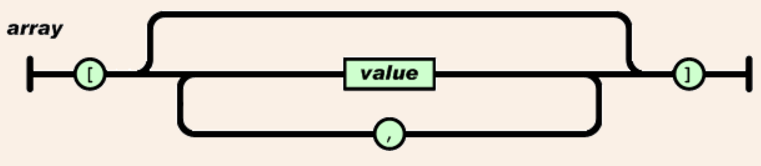
Each line in a CSVJSON file is defined as follows:
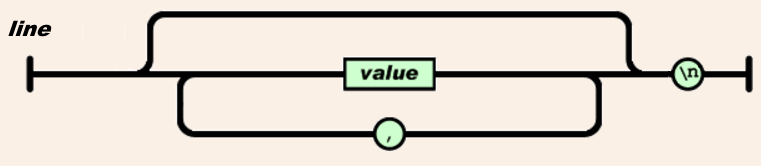
That is, each line in a CSVJSON file is actually just like a JSON array, stripped of the openning left square bracket ([) and with a newline replacing the closing right bracket (]). Newline may only appear after the last value while non-new-line whitespaces around values are ignored. Lines with nothing but whitespaces are ignored.
Samples
Below are examples of valid CSVJSON content
Regular CSV
1,"John","12 Totem Rd. Aspen",true
2,"Bob",null,false
3,"Sue","Bigsby, 345 Carnival, WA 23009",false
CSV with headers row
"id","name","address","regular"
1,"John","12 Totem Rd. Aspen",true
2,"Bob",null,false
3,"Sue","Bigsby, 345 Carnival, WA 23009",false
CSV with data containing quotes and commas
"id","name","address","regular"
1,"John","12 Totem Rd., Aspen",true
2,"Bob",null,false
3,"Sue","\"Bigsby\", 345 Carnival, WA 23009",false
CSV with complex headers
{"field":"id","type":"int"},{"field":"name","type":"string"},{"field":"address","type":"string"},{"field":"regular","type":"boolean"}
1,"John","12 Totem Rd. Aspen",true
2,"Bob",null,false
3,"Sue","Bigsby, 345 Carnival, WA 23009",false
CSV with array data
1,"directions",["north","south","east","west"]
2,"colors",["red","green","blue"]
3,"drinks",["soda","water","tea","coffe"]
4,"spells",[]
CSV with all kinds of data
"index","value1","value2"
"number",1,2
"boolean",false,true
"null",null,"non null"
"array of numbers",[1],[1,2]
"simple object",{"a": 1},{"a":1, "b":2}
"array with mixed objects",[1,null,"ball"],[2,{"a": 10, "b": 20},"cube"]
"string with quotes","a\"b","alert(\"Hi!\")"
"string with bell&newlines","bell is \u0007","multi\nline\ntext"
Use Cases
Common textual database table export format
CSVJSON is an ideal format for exporting database tables to text files. Here are some benefits:
- Being based on UTF-8 it can reliably maintain text from different languages.
- It has a standard concept of nulls.
- It can deal with modern database features like rows with embedded objects and arrays. A good example is coordinates and polygons in GIS (Geographical Information Systems).
- Being based on JSON, there is large variety of high quality formatters and parsers in virtually every programming language.
- The CSVJSON header line can be used to store each column definition like: {“name”:”ID”,”type”:”number”},{“name”:”TITLE”,”type”:”string”}}
Simple, low maintenance, big-data storage format
Many big-data projects have to do significant work dealing with the messiness of the common CSV format. CSVJSON stores tabluar data naturally with high fidelity. It easily captures all the required semantics including character encoding, representation of null values among others. In addition CSVJSON support parallel processing by arbitrarily splitting the files into several parts because newlines may only appear between lines. So, if a 10GB worth of CSVJSON needs to be processed, one can spawn 10 parallel tasks where each task processes aruond 1GB of data and all but the first just skip forward past the next newline and starts there, ending with the last line that started within the 1GB range. The CSVJSON file may also be snappy-compressed to and still allow for parallel processing.
Questions and Answers
- How is CSVJSON related to JSON Lines JSON Lines.
- The JSON Lines format is a textual format for tabular data where each line is a valid JSON value. The CSVJSON format is a textual format for tabular data where each line has zero or more valid JSON values separated by commas. One can view JSON Lines as a special case of CSVJSON. CSVJSON has the benefit over JSON Lines in that for numbers and 'simple' strings, it aligns with the regular CSV format.
- What is the recommended file type extension for a CSVJSON file?
- The recommended file format for CSVJSON files is .csvj although one can also use the .csv file extension because a valid CSVJSON file is also a comma-seperated-values file (with JSON rules).
- Can CSVJSON data contain complex JSON objects?
- Sure. As long as the included JSON object does not have unescaped newlines (that is, newlines must be encoded using \n). Note that when including JSON objects in a CSVJSON line, there is little chance a regular CSV parser would be able to read it.
- Is there a recommended mime type for CSVJSON?
- The recommended mime type for CSVJSON is text/csvjson. Note that this mime type is not yet formally registered.
- How are newlines defined?
- Both \n and \r\n can serve as newlines meaning the format should work regardless of whether the file was generated on a Windows or a Linux/Unix based system.
- Is there actually software out there that support CSVJSON?
- I am not currently aware of parsers/serializers that support the CSVJSON variant - as such parsers, serializers and software tools supporting CSVJSON appear, I will list them below. If you have created or are aware of such software, please open an issue on Github issues.
- Wouldn't using \1 or similar control character as delimiter enable better performance?
- Using a delimiter like \1 or any other character that cannot appear within JSON string literals or within raw JSON can make the parsing faster. This will be the case when trying to skip complex values that are not of interest - one can skip to the next \1 very quickly. This will save power and thus be 'greener' but then it would not be so easily compatible with common JSON parsers and this is a high price to pay.
- What configuration items may be expected in CSVJSON parsers?
- The CSVJSON is well defined without complex parsing instructions a typical CSV parser needs. However it would be useful to have several common CSVJSON-related configuration options:
- csvjson={true|false} - for a general CSV parser, this option will configure it to parse CSVJSON input
- withObjects={true|false} - parsing JSON object and array values in a CSVJSON file can complicate the parser. For high-performance parsers where there is no need for parsing objects or array values, this option can tell the parser it does not need to deal with that additional complexity, or otherwise let the parser throw an error in case it does not support parsing objects or arrays but it is still asked to.
- withHeader={true|false} - indicate whether the first line contain comma-seperated column names
Software that supports CSVJSON
CSVJSON is more expressive than CSV (whose common use is documented by RFC-4180). As a result, there are many cases where products and libraries that can read CSV would fail to read CSVJSON due, for example, to escaping rules and embedded objects. Given CSVJSON’s simplicity and utility more tools and libraries will support it over time.
- csvjson.com - Online tools to convert popular data formats
- The csvjson.com web application offers conversions between JSON and CSV, and offers support for the CSVJSON format as well. Thanks Martin Drapeau.